linux内核中qspinlock锁的优缺点分析
- qspinlock 是一种为现代多核系统设计的先进混合自旋锁。它巧妙地融合了两种经典锁的优点:既继承了票据锁(ticket lock)的公平性,又借鉴了 MCS 锁优异的可扩展性。
1. 传统spinlock:
- 多个等待的 CPU 核心中,谁先获得锁并无保证,存在公平性问题,同时缓存一致性开销大(如MESI),CPU核心越大,cache需求越厉害,缺乏可扩展性
2. Ticket spinlock
1 | |
- 解决了公平问题,防止某些 CPU 永远得不到锁,但所有核都轮询同一个owner变量,read cache line成热点,限制扩展性
3. MCS lock
- 本质上是一种基于链表结构的自旋锁,每个CPU有一个对应的节点(锁的副本),基于各自不同的副本变量进行等待,锁本身是共享的,但队列节点是线程自己维护的,每个CPU只需要查询自己对应的本地cache line,仅在这个变量发生变化的时候,才需要读取内存和刷新这条cache line, 不像 classic/ticket对共享变量进行spin
1 | |
- 每个 CPU 线程创建的node 是独立的,每个线程都有自己的 node 实例。但是结构体中多了一个指针使结构体变大了,导致了“内存开销问题”:MCS 锁把竞争带来的 cache-line 抖动降低了,但牺牲了一些内存和部分结构管理的成本。
4. qspinlock
include/asm-generic/qspinlock_types.h: 锁数据结构
1 | |
When NR_CPUS < 16K: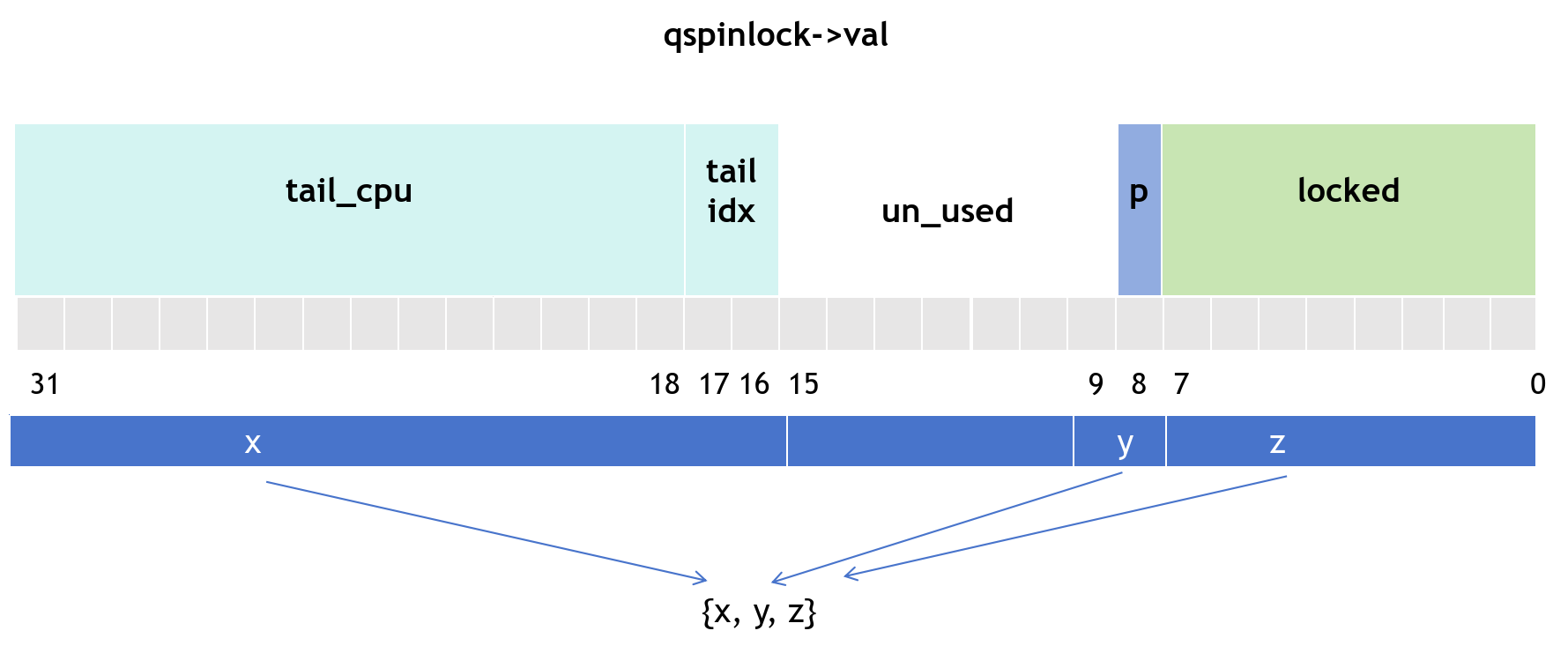
locked:用来表示这个锁是否被人持有(0:无,1:有)pending:可以理解为最优先持锁位,即当unlock之后只有这个位的CPU最先持锁,也有1和0tail:有idx+CPU构成,用来标识等待队列的最后一个节点。tail_idx:就是index,它作为mcs_nodes数组的下标使用tail_CPU:用来表示CPU的编号+1,+1因为规定tail为0的时候表示等待队列中没有成员
kernel/locking/mcs_spinlock.h
1 | |
locked = 1:只是说锁传到了当前加节点,但是当前节点还需要主动申请锁(qspinlock -> locked = 1)count:针对四种上下文用于追踪当前用了第几个 node(即 idx),最大为4,不够用时就fallback不排队直接自旋
kernel/locking/qspinlock.c:
1 | |
- 一个 CPU 上可能嵌套多个锁,
qnodes针对四种上下文情况下,例:进程上下文中发生中断后再次获取锁 - PER_CPU的优点是快,可防止抢锁时再mallock或临时分配导致延迟,成本等问题
申请锁:
- 快速申请
include/asm-generic/qspinlock.h
1 | |
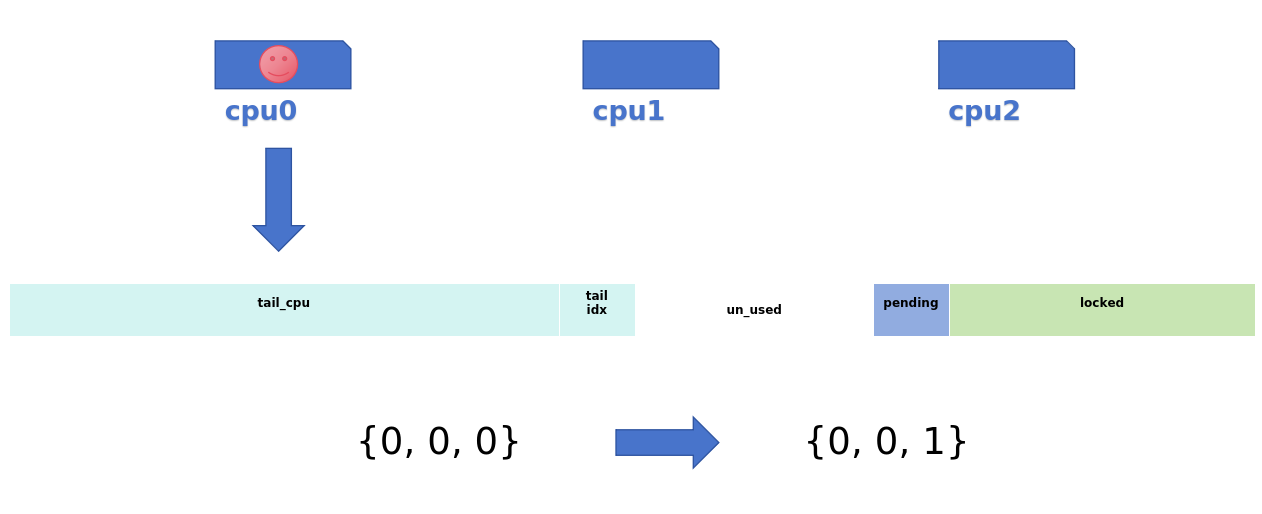
- 中速申请
- 快速申请失败,queue中为空时,设置锁的pending位
- 再次检测(检查中间是否有其它cpu进入)
- 一直循环检测locked位
- 当locked位为0时,清除pending位获得锁
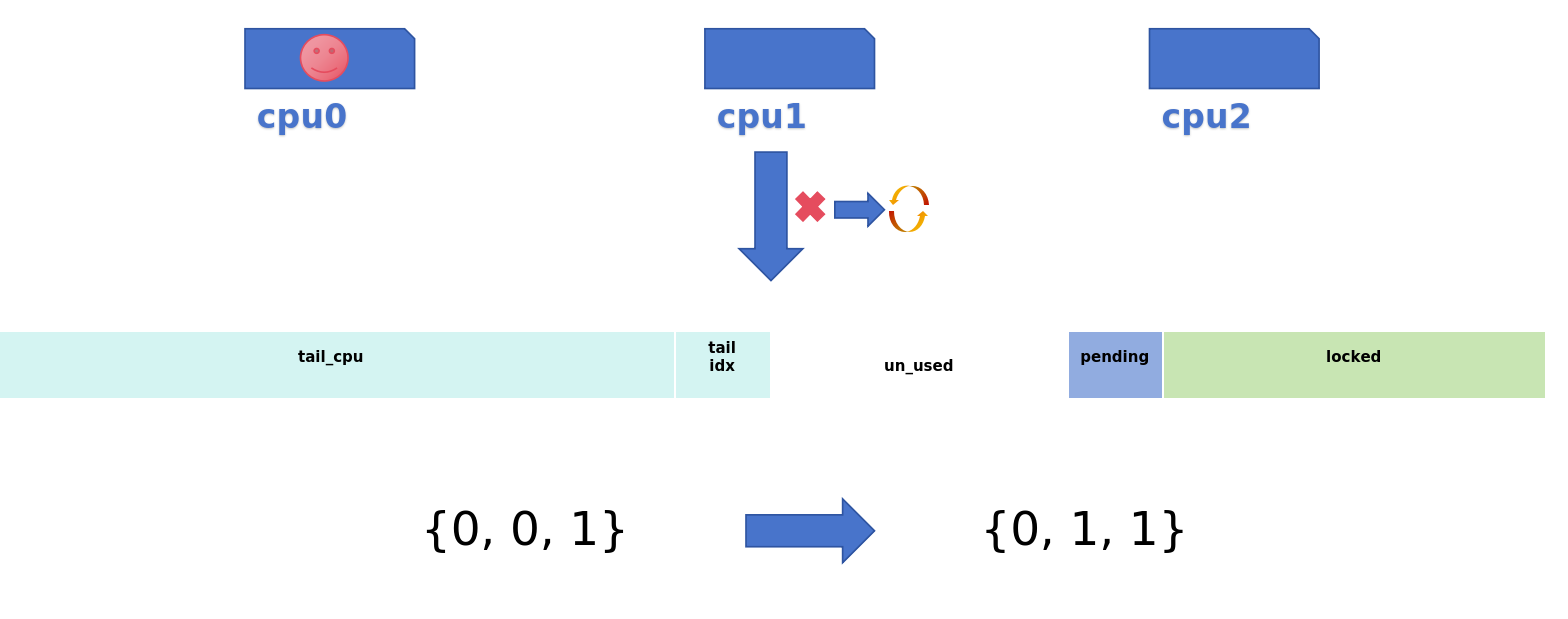
- 慢速申请
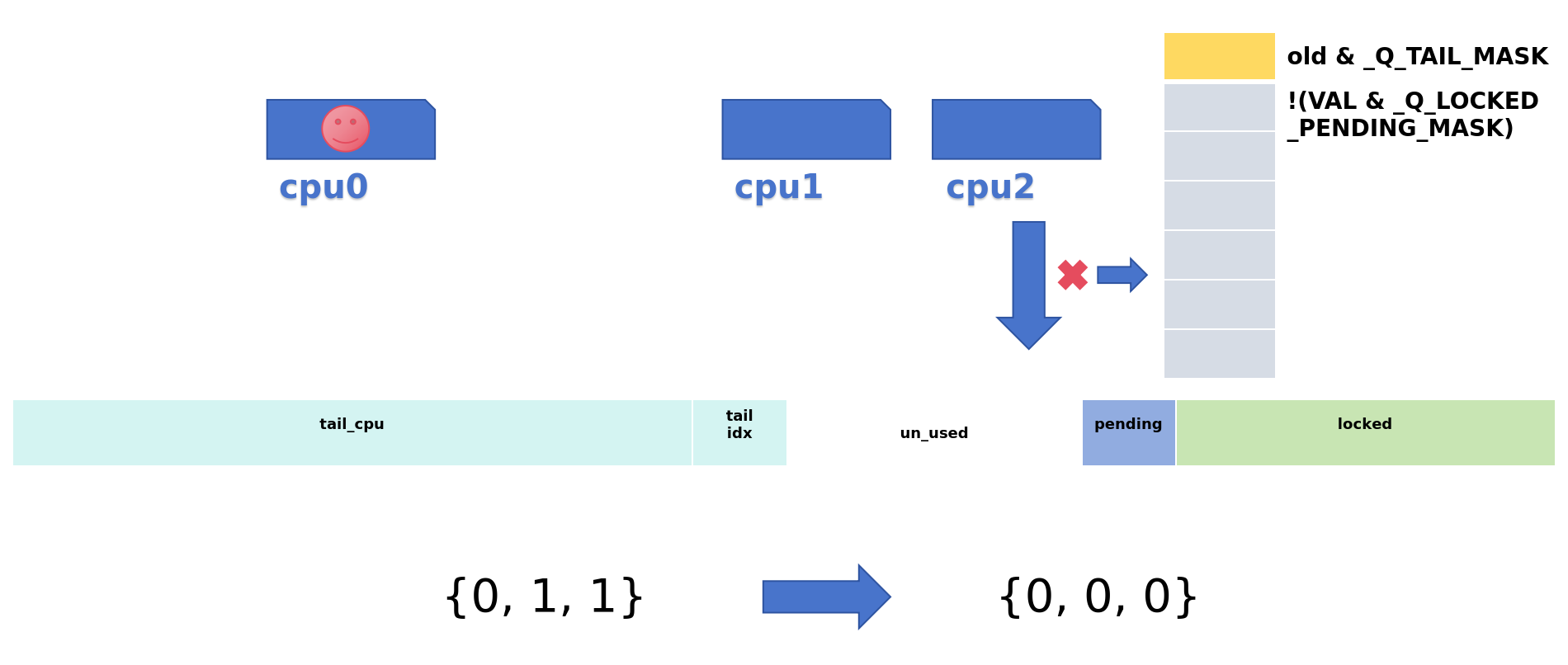
| 申请 | 操作 |
|---|---|
| 快速申请 | 这个锁当前没有人持有,直接通过cmpxchg()设置locked域即可获取了锁 |
| 中速申请 | 锁已经被人持有,但是MCS链表没有其他人,有且仅有一个人在等待这个锁。设置pending域,表示是第一顺位继承者,自旋等待lock-> locked清0,即锁持有者释放锁 |
| 慢速申请 | 进入到queue中自旋等待,若为队列头(队列中没有等待的cpu),说明它已排到最前,可以开始尝试获取锁;否则,它会自旋等待前一个节点释放锁,并通知它可以尝试获取锁了 |
end:
如果只有1个或2个CPU试图获取锁,那么只需要一个4字节的qspinlock就可以了,其所占内存的大小和ticket spinlock一样。当有3个以上的CPU试图获取锁,则需要(N-2)个MCS node
qspinlock中加入”pending”位域的意义,如果是两个CPU试图获取锁,那么第二个CPU只需要简单地设置”pending”为1,而不用创建一个MCS node
试图加锁的CPU数目超过3个,使用ticket spinlock机制就会造成多个CPU的cache line刷新的问题,而qspinlock可以利用MCS node队列来解决这个问题
在多核争用严重场景下,qspinlock 让等待者在本地内存区域自旋,减少了锁的缓存抖动和对总线的竞争消耗
RISCV_QUEUED_SPINLOCKS 只应在平台(RISC-V)具有 Zabha 或 Ziccrse 时启用,不支持的情况不要选用
优先级反转问题,queue会保证了FIFO提高了公平性,但它无法感知任务的优先级,可能因为排在队列前方的低优先级任务未释放锁而发生等待,从而导致 优先级反转
linux内核中qspinlock锁的优缺点分析

