Linux bpf技术解析及libbpf的使用(基于riscv-k1)
- 了解ebpf并在riscv平台上支持ebpf, 最后理解并使用libbpf库中的示例
BPF 和 eBPF
- BPF (extened Berkeley Packet Filter):
- BPF提供了一种在各种内核事件和应用程序事件发生时运行一小段程序的机制。该技术将内核变成完全可编程,允许用户定制和控制它们的系统,以解决现实问题。提供了一套内核接口/bpf() 系统调用集合。
- BPF是一项灵活而高效的技术,由指令集、存储对象和辅助函数等几部分组成。由于它采用了虚拟指令集规范,因此也可将它视作一种虚拟机实现。这些指令由Linux内核的BPF运行时模块执行。
- eBPF(extened Berkeley Packet Filter):
- 扩展版 BPF(64-bit regs、更多指令、复杂验证、maps、helper 函数、更广泛用途)。现在说 BPF/ eBPF 基本都指 eBPF。
原理
eBPF 的工作原理主要分为三个步骤:加载、编译和执行。
eBPF 需要在内核中运行。这通常是由用户态的应用程序完成的,它会通过系统调用来加载 eBPF 程序。在加载过程中,内核会将 eBPF 程序的代码复制到内核空间。
eBPF 程序需要经过编译和执行。这通常是由
Clang/LLVM的编译器完成,然后形成字节码后,将用户态的字节码装载进内核,Verifier会对要注入内核的程序进行一些内核安全机制的检查,这是为了确保 eBPF 程序不会破坏内核的稳定性和安全性。在检查过程中,内核会对 eBPF 程序的代码进行分析,以确保它不会进行恶意操作,如系统调用、内存访问等。如果 eBPF 程序通过了内核安全机制的检查,它就可以在内核中正常运行了,其会通过通过一个JIT编译步骤将程序的通用字节码转换为机器特定指令集,以优化程序的执行速度。JIT:(即时编译,Just-In-Time compilation): 动态编译技术,它介于解释执行和提前编译(AOT, Ahead-Of-Time)之间。
- 解释执行:代码一行行解释运行(如 Python、早期 JavaScript),启动快,但运行慢。
- 提前编译(AOT):代码在运行前全部编译成目标机器码(如 C/C++),运行快,但灵活性差。
- JIT:在运行时,把中间表示(IR, bytecode)翻译成机器码,并缓存起来,下次直接运行机器码。既能接近原生性能,又保留了灵活性。
- JIT 的本质过程:程序一开始以 字节码(或中间表示)形式运行。运行过程中,JIT 编译器发现“这段代码执行得很频繁”(热点代码),于是触发编译。把字节码即时翻译成当前 CPU 架构的机器码(x86、ARM、RISC-V 等)。后续直接执行机器码(免去解释器逐条解释的开销)。
Clang/LLVM:
- Clang:C/C++ 前端(把
C/C++/Objective-C源转成通用的标准化的中间语言LLVM IR)。- 词法分析:把代码拆成一个个单词(token),比如 int, main, (, ), {, }。
- 语法分析:检查这些单词组合起来是否符合 C/C++ 的语法规则。如果写了 int main{) 这种错误,Clang 就在这一步报错。
- 生成中间表示 (IR):如果语法正确,Clang 会把代码转换成一种通用的、与具体计算机架构无关的格式,这就是 LLVM Intermediate Representation (LLVM IR)。
- LLVM:编译器后台/工具链,接收Clang生成的LLVM IR, 进行一系列加工,生成可执行的机器码。
- 优化 (Optimization):LLVM 会对 IR 进行大量的优化。比如删除无用的代码、合并重复的计算、展开循环等等,让最终的程序跑得更快、体积更小。这是 LLVM 的核心优势之一。
- 代码生成 (Code Generation):这是最关键的一步。LLVM 会根据你指定的 “目标平台 (Target)”,将优化后的 IR 翻译成该平台专属的机器指令。
可移植性:Clang/LLVM 支持很多后端/目标(x86/arm/bpf 等)。当你用 -target bpf 时,Clang 输出的是 eBPF 字节码(虚拟指令),不是 x86 或 arm 机器码。这个字节码理论上可以在任何支持 eBPF 的内核上运行(但内核版本/ABI 细节会影响,CO-RE/BTF 出现就是为了解决这类兼容性问题)。最终在内核里,JIT 会把字节码翻译成当前 CPU 的本地机器码。
所以,Clang/LLVM 实现了第一层可移植性(源码 -> eBPF 字节码),而内核的 JIT 编译器实现了第二层可移植性(eBPF 字节码 -> 具体 CPU 机器码)。
ebpf结构图
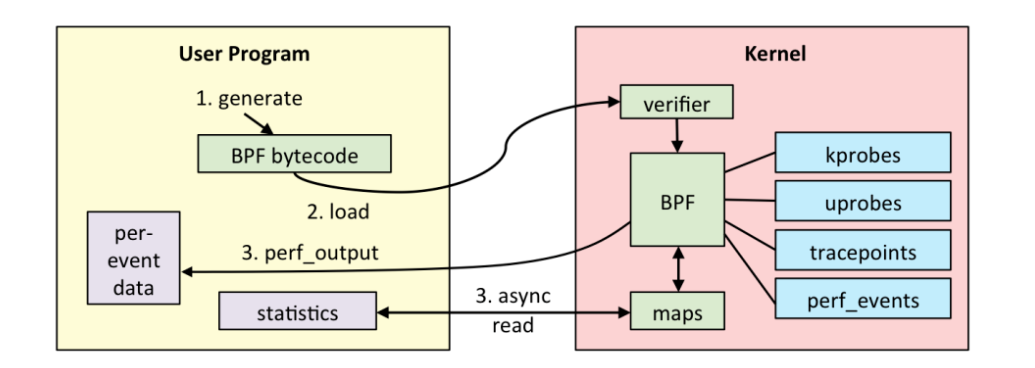
用户空间程序与内核中的 BPF 字节码交互的流程主要如下:
- 我们可以使用 LLVM 或者 GCC 工具将编写的 BPF 代码程序编译成 BPF 字节码;
- 然后使用加载程序 Loader 将字节码加载至内核;内核使用验证器(verfier) 组件保证执行字节码的安全性,以避免对内核造成灾难,在确认字节码安全后将其加载对应的内核模块执行;BPF 观测技术相关的程序程序类型可能是 kprobes/uprobes/tracepoint/perf_events 中的一个或多个,其中:
kprobes:实现内核中动态跟踪。kprobes 可以跟踪到 Linux 内核中的导出函数入口或返回点,但是不是稳定 ABI 接口,可能会因为内核版本变化导致,导致跟踪失效。
uprobes:用户级别的动态跟踪。与 kprobes 类似,只是跟踪用户程序中的函数。
tracepoints:内核中静态跟踪。tracepoints 是内核开发人员维护的跟踪点,能够提供稳定的 ABI 接口,但是由于是研发人员维护,数量和场景可能受限。
perf_events:定时采样和 PMC。
内核中运行的 BPF 字节码程序可以使用两种方式将测量数据回传至用户空间
- maps 方式可用于将内核中实现的统计摘要信息(比如测量延迟、堆栈信息)等回传至用户空间;
- perf-event 用于将内核采集的事件实时发送至用户空间,用户空间程序实时读取分析;
用途和优势
- 用途
- 网络监控:eBPF 可以用于捕获网络数据包,并执行特定的逻辑来分析网络流量。例如,可以使用 eBPF 程序来监控网络流量,并在发现异常流量时进行警报。
- 安全过滤:eBPF 可以用于对网络数据包进行安全过滤。例如,可以使用 eBPF 程序来阻止恶意流量的传播,或者在发现恶意流量时对其进行拦截。
- 性能分析:eBPF 可以用于对内核的性能进行分析。例如,可以使用 eBPF 程序来收集内核的性能指标,并通过特定的接口将其可视化。这样,可以更好地了解内核的性能瓶颈,并进行优化。
- 虚拟化:eBPF 可以用于虚拟化技术。例如,可以使用 eBPF 程序来收集虚拟机的性能指标,并进行负载均衡。这样,可以更好地利用虚拟化环境的资源,提高系统的性能和稳定性。
- 优势
- 安全:验证器确保了任何 eBPF 程序都不会搞垮内核。
- 可移植:同一份 eBPF 字节码,理论上可以在任何架构(x86, ARM, RISC-V)的 Linux 内核上运行,因为 JIT(见下文) 会为它们翻译出对应的原生机器码。
- 高性能:因为 JIT 的存在,最终运行的是原生机器码,速度接近于原生内核代码。
在k1上安装并配置ebpf的环境和工具
- 烧录官方提供的bianbu镜像v3.0
- 但是启动后发现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17root@k1:/sys/kernel# cat /boot/config-6.1.15 | grep BPF
CONFIG_BPF=y
CONFIG_HAVE_EBPF_JIT=y
BPF subsystem
CONFIG_BPF_SYSCALL=y
CONFIG_BPF_JIT is not set # JIT 编译器被关闭 (JIT Compiler is Disabled)
CONFIG_BPF_UNPRIV_DEFAULT_OFF=y
end of BPF subsystem
CONFIG_CGROUP_BPF=y
CONFIG_NETFILTER_XT_MATCH_BPF=y
CONFIG_BPFILTER is not set
CONFIG_NET_CLS_BPF is not set # 缺少网络核心功能
CONFIG_BPF_STREAM_PARSER is not set
CONFIG_NBPFAXI_DMA is not set
CONFIG_BPF_EVENTS=y
root@k1:/sys/kernel# grep BTF /boot/config-x.x.x
CONFIG_DEBUG_INFO_BTF=y # 内核没有编译进 BTF (BPF Type Format) 信息
- 编译源码替换内核镜像
备份旧文件
1
2
3cd /boot
cp vmlinuz-6.6.63 vmlinuz-6.6.63.bak
cp spacemit/6.6.63/k1-x_evb.dtb spacemit/6.6.63/k1-x_evb.dtb.bak- vmlinuz只有一个,但是dtb有多个,需要确定是哪一个
- 这里查看dtb和model输出
1
2
3
4
5
6
7
8
9
10
11root@k1:~# ls /boot/spacemit/6.6.63/
k1-x_baton-camera.dtb k1-x_fpga.dtb k1-x_MUSE-Card.dtb k1-x_som.dtb
k1-x_bit-brick.dtb k1-x_FusionOne.dtb k1-x_MUSE-N1.dtb k1-x_uav.dtb
k1-x_deb1.dtb k1-x_InnoBoard-Pi.dtb k1-x_MUSE-Paper2.dtb k1-x_ZT001H.dtb
k1-x_deb2.dtb k1-x_lpi3a.dtb k1-x_MUSE-Paper-mini-4g.dtb k1-x_ZT_RVOH007.dtb
k1-x_evb.dtb k1-x_LX-V10.dtb k1-x_MUSE-Pi.dtb m1-x_milkv-jupiter.dtb
k1-x_evb.dtb.bak k1-x_milkv-jupiter.dtb k1-x_MUSE-Pi-Pro.dtb
k1-x_fpga_1x4.dtb k1-x_MINI-PC.dtb k1-x_NetBridge-C1.dtb
k1-x_fpga_2x2.dtb k1-x_MUSE-Book.dtb k1-x_RV4B.dtb
root@k1:~# cat /proc/device-tree/model
spacemit k1-x deb1 boardroot- 然后就感觉可能是其中的k1-x_deb1.dtb
- 但是不放心就又去查看Uboot启动时加载的dtb
1
2
3
4
5
6=> printenv boot
boot_default boot_device boot_devnum bootcmd bootdelay bootfs_devname
bootfs_part bootmenu_0 bootmenu_1 bootmenu_2 bootmenu_3 bootmenu_4
bootmenu_5 bootmenu_6 bootmenu_7 bootmenu_8 bootmenu_9 bootmenu_delay
=> printenv bootcmd
bootcmd=run autoboot; echo "run autoboot"- 再查看autoboot: 显示如果从 eMMC 启动,那么就执行 mmc_boot 这个脚本。
1
2printenv autoboot
autoboot=if test ${boot_device} = nand; then run nand_boot; elif test ${boot_device} = nor; then run nor_boot; elif test ${boot_device} = mmc; then run mmc_boot; fi;- 查看mmc_boot: 执行 detect_dtb 脚本。
1
2
3
4=> printenv mmc_boot
mmc_boot=echo "Try to boot from ${bootfs_devname}${boot_devnum} ..."; run commonargs; run set_mmc_root; run set_mmc_args; run detect_dtb; run loadknl; run loaddtb; run loadramdisk; bootm ${kernel_addr_r} ${ramdisk_combo} ${dtb_addr}; echo "########### boot kernel failed by d
=> printenv detect_dtb
detect_dtb=echo "product_name: ${product_name}"; run dtb_env; echo "select ${dtb_name} to load";- 继续查看dev_env
1
2
3
4
5=> printenv dtb_env
dtb_env=if test -n "${product_name}"; then if test "${product_name}" = k1_evb; then setenv dtb_name ${dtb_dir}/k1-x_evb.dtb; elif test "${product_name}" = k1_deb1; then setenv dtb_name ${dtb_dir}/k1-x_deb1.dtb; elif test "${product_name}" = k1_deb2; then setenv dtb_name ${dt=> printenv product_name
product_name=k1-x_deb1
=> printenv dtb_name
dtb_name=k1-x_evb.dtb - 最后发现加载的dtb为k1-x_exb.dtb
- 最后备份并且替换的是k1-x_exb.dtb文件
- vmlinuz只有一个,但是dtb有多个,需要确定是哪一个
clone linux6.6内核源码
- git clone https://gitee.com/bianbu-linux/linux-6.6.git –depth = 1
在原有基础上检查并打开配置并编译
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21make k1_defconfig
make menuconfig # 建议手动开启,可以打开对应更高级配置
# eBPF 核心与性能 (必须开启)
./scripts/config --enable BPF_JIT
./scripts/config --enable BPF_JIT_ALWAYS_ON
./scripts/config --enable DEBUG_INFO_BTF
# eBPF 网络功能 (推荐开启)
./scripts/config --enable NET_CLS_BPF
./scripts/config --enable NET_ACT_BPF
./scripts/config --enable XDP_SOCKETS
# eBPF 追踪与调试功能 (必须开启)
./scripts/config --enable BPF_EVENTS
./scripts/config --enable KPROBES
./scripts/config --enable UPROBES
./scripts/config --enable TRACEPOINTS
./scripts/config --enable FTRACE
./scripts/config --enable KPROBE_EVENTS
./scripts/config --enable UPROBE_EVENTS
./scripts/config --enable FTRACE_SYSCALLS- 这里编译时报错,发现工具链不支持zicond扩展,应该是当时编译时没有开启,重新编译
1
2
3
4
5CC scripts/mod/empty.o
HOSTCC scripts/mod/mk_elfconfig
CC scripts/mod/devicetable-offsets.s
Assembler messages:
错误: rv64imac_zicond_zihintpause_zba_zbc_zbs: unknown prefixed ISA extension `zicond'- 编译
1
2
3
4# 假设你的安装目录还是 /opt/riscv
./configure --prefix=/opt/riscv --with-arch=rv64gc_zba_zbb_zbc_zbs_zicond
# 这个过程会比较长,请耐心等待
make -j$(nproc) linux- 重新编译工具链后内核可完成编译,替换镜像和设备树
1
2mv /home/share/Image /boot/vmlinuz-6.6.63
mv /home/share/k1-x_evb.dtb /boot/spacemit/6.6.63/k1-x_evb.dtb- 确保写入磁盘并重启
1
2sync
reboot
配置libbpf并使用libbpf-bootstrap库中示例
- clone 仓库
1
2
3git clone https://github.com/libbpf/libbpf-bootstrap.git --depth=1
git submodule update --init --recursive
cd libbpf-bootstrap - 编译
1
2cd examples/c
make
- clone 仓库
刚开始打算在pc上交叉编译,但是尝试了好久都没成功编译出来,于是在开发板上直接本地编译了
1
2
3
4- sudo apt update
- sudo apt install -y build-essential clang llvm libelf-dev libz-dev git
- cd libbpf-bootstrap/examples/c
- make编译成功
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27#编译成功
root@k1:~# ls repo/libbpf-bootstrap/examples/c/
bootstrap kprobe lsm.c minimal_ns sockfilter.c tc.c
bootstrap.bpf.c kprobe.bpf.c Makefile minimal_ns.bpf.c sockfilter.h uprobe
bootstrap.c kprobe.c minimal minimal_ns.c task_iter uprobe.bpf.c
bootstrap.h ksyscall minimal.bpf.c profile.bpf.c task_iter.bpf.c uprobe.c
CMakeLists.txt ksyscall.bpf.c minimal.c profile.c task_iter.c usdt
fentry ksyscall.c minimal_legacy profile.h task_iter.h usdt.bpf.c
fentry.bpf.c lsm minimal_legacy.bpf.c sockfilter tc usdt.c
fentry.c lsm.bpf.c minimal_legacy.c sockfilter.bpf.c tc.bpf.c xmake.lua
# 成功运行
root@k1:~# ./repo/libbpf-bootstrap/examples/c/bootstrap
TIME EVENT COMM PID PPID FILENAME/EXIT CODE
15:11:17 EXEC ls 692 682 /usr/bin/ls
15:11:17 EXIT ls 692 682 [0] (3ms)
15:11:23 EXEC cat 693 682 /usr/bin/cat
15:11:26 EXIT cat 693 682 [0] (3732ms)
15:11:33 EXEC touch 694 682 /usr/bin/touch
15:11:33 EXIT touch 694 682 [0] (2ms)
15:11:33 EXEC ls 695 682 /usr/bin/ls
15:11:33 EXIT ls 695 682 [0] (3ms)
15:11:36 EXEC rm 696 682 /usr/bin/rm
15:11:36 EXIT rm 696 682 [0] (1ms)
15:11:37 EXIT bash 682 681 [0]
15:11:38 EXIT sshd-session 681 671 [255]
15:11:38 EXIT sshd-session 671 669 [255]
15:11:38 EXIT (sd-close) 697 1 [0]BPF helper functions
| 函数 | 功能 | 用法示例 |
|---|---|---|
bpf_get_current_pid_tgid() |
获取当前进程 PID 和 TID | u64 id = bpf_get_current_pid_tgid(); pid = id >> 32; tid = id & 0xFFFFFFFF; |
bpf_get_current_uid_gid() |
当前进程的 UID/GID | 用户态安全权限判断 |
bpf_get_current_comm(char *buf, int size) |
获取当前进程名 | 用于日志输出或过滤 |
bpf_ktime_get_ns() |
返回内核时间戳(ns) | 用于计算函数耗时 |
bpf_map_lookup_elem() |
访问 BPF map 中的元素 | 统计计数/缓存数据 |
bpf_map_update_elem() |
更新 map 中的值 | 更新计数/状态 |
bpf_map_delete_elem() |
删除 map 元素 | 清理数据 |
bpf_probe_read() / bpf_probe_read_str() |
从内核空间安全读取数据 | 读取 struct task_struct 或驱动数据 |
bpf_perf_event_output() |
发送数据到用户态 perf buffer | 用于实时上报事件 |
bpf_trace_printk() |
打印日志到 trace_pipe | 调试 / 简单监控 |
第一个demo
- 早期无CO-RE模式,见此博客demo
- bpf_load.c + libelf + 手动链接 libbpf, 需要手动配置头文件,依赖内核版本源码,使用辅助脚本等
- 现代CO-RE模式
- libbpf 库 + BPF Skeleton (.skel.h), libbpf 库和 bpftool 工具为你处理所有底层的繁琐工作(如ELF解析、map创建、程序加载、挂载)。
- CO-RE (一次编译,到处运行):通过 vmlinux.h 和 BTF,代码不强依赖特定内核版本,可移植性极高。
目的: 让一个 eBPF 程序只监控加载它自身的那个进程的 write 系统调用。
- minimal_ns.bpf.c: 这是运行在内核中的 eBPF 代码,它会被附加到 write 系统调用的跟踪点上。
1 | |
| 关键点 | 作用 |
|---|---|
| 全局变量 (my_pid, dev, ino) | 这不是普通的全局变量。在 eBPF 中,定义在顶层的变量会被编译器放入 ELF 文件的特定段(如 .data, .bss, .rodata)。libbpf 在加载 BPF 程序时,能够识别这些变量,并允许用户态代码在 bpf_object__load() 之前对它们进行修改。这正是用户态向内核态传递配置的桥梁。 |
| bpf_get_ns_current_pid_tgid() | 这是一个非常重要的辅助函数。在复杂的容器环境中,一个进程的 PID 在容器内和在宿主机上是不同的。这个函数允许我们查询一个进程在特定PID命名空间中的 PID。它通过设备号(dev)和 inode 号(ino)来唯一确定一个命名空间。 |
| 过滤逻辑 | 这是整个 BPF 程序的核心。它确保了只有“目标”进程(即加载它自己的那个用户态程序)的 write 调用才能触发 bpf_printk。所有其他进程的 write 调用都会在 if 判断那里被提前过滤掉。 |
- minimal_ns.c: 这是运行在用户空间的普通 C 程序,负责加载、设置、附加和销毁 eBPF 程序。
1 | |
| 关键点 | 作用 |
|---|---|
| minimal_ns.skel.h | 这是 libbpf-bootstrap 的魔法核心。构建系统会使用 bpftool 工具根据你的 .bpf.c 文件自动生成这个头文件。它包含了 struct minimal_ns_bpf 的定义,以及 __open, __load, __attach, __destroy 等生命周期管理函数。 |
| skel->bss->… | 这就是访问 BPF 全局变量的方式。skel 指向整个 BPF 对象的句柄,skel->bss 是一个指向 BPF 程序 .bss 段变量的结构体。你可以像访问普通结构体成员一样读写它们。 |
| stat(“/proc/self/ns/pid”, &sb): 这是获取当前进程 PID 命名空间标识符的标准方法。sb.st_dev 和 sb.st_ino 的组合在整个系统中是唯一的。 | |
| fprintf(stderr, “.”) | 这行代码不仅仅是为了在终端上显示进度。它的本质是调用 write 系统调用。因为 BPF 程序监控的就是 write,并且只对自己这个 PID 感兴趣,所以这个调用就是触发 BPF 程序执行的“扳机”。 |
执行流程:
- 用户态程序启动。
- 它通过 stat 系统调用获取自己所在的 PID 命名空间标识(dev 和 ino),并通过 getpid() 获取自己的 PID。
- 它通过 BPF skeleton (skel->bss->…) 将这三个值写入 BPF 程序的全局变量中。
- 它调用 __load() 将配置好的 BPF 程序加载进内核。
- 它调用 __attach() 将 BPF 程序挂载到 write 系统调用的入口。
- 用户态程序进入无限循环,每秒调用一次 fprintf,这会触发 write 系统调用。
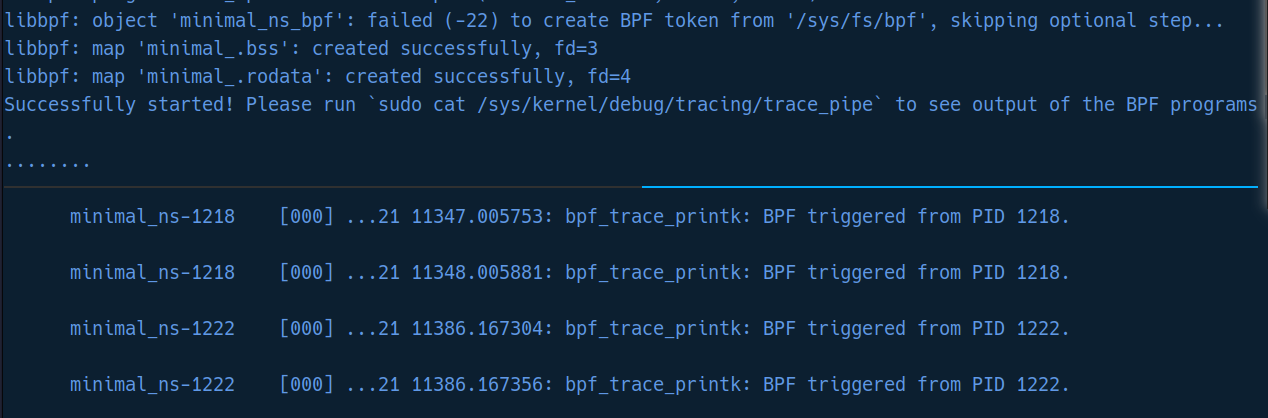
- 内核中的 BPF 程序被触发,它检查发现是目标进程,于是打印一条日志。
- 我们在另一个终端通过 cat /sys/kernel/debug/tracing/trace_pipe 就能看到这条日志。
运行结果:
相关仓库
libbpf-bootstrap(仓库)- 定位: 一个由
libbpf官方维护的最佳实践模板和入门脚手架。 - 价值: 它展示了如何正确地构建一个现代、基于
libbpf+ CO-RE 的 eBPF 程序。它的Makefile和示例代码封装了所有复杂的构建细节:- 如何调用
Clang将.bpf.c编译成.bpf.o。 - 如何使用
bpftool基于.o文件生成骨架头文件 (.skel.h)。 - 如何将用户态的 C 程序与
libbpf库链接起来。 - 对于初学者来说,克隆这个仓库是学习
libbpf开发最直接、最标准的方式。
- 如何调用
- 定位: 一个由
awesome-ebpf(仓库)- 定位: 一个精心策划的 eBPF 资源聚合清单。
- 价值: 如果你想了解 eBPF 生态的全貌,这里是你的起点。它系统地收集和分类了互联网上几乎所有与 eBPF 相关的优秀资源,包括但不限于:
- 入门教程和文档
- 知名开源项目 (如 Cilium, Falco)
- 实用的开发工具
- 深度技术博客和文章
- 会议演讲和视频
Linux bpf技术解析及libbpf的使用(基于riscv-k1)

